

Pese a la diversidad de compuestos bioactivos presentes en la naturaleza y a la gran cantidad de aplicaciones que éstos presentan, se estima que solo el 1% de estos compuestos son conocidos.
LINNA es nuestra plataforma de Inteligencia Artificial, una combinación de diferentes modelos predictivos con una aspiración única: descifrar la naturaleza para identificar nuevos compuestos bioactivos desconocidos hasta el momento y aplicar nuevos usos para aquellos conocidos a una velocidad y precisión inalcanzables para el ser humano.
Más información sobre la capacidad de análisis de LINNA®
LINNA utiliza algunas de estas metodologías avanzadas de aprendizaje para entender el mundo natural. Por ejemplo, predice las complejas respuestas de las redes de interacción de proteínas, entendiendo los sistemas regulatorios y el impacto de pequeñas perturbaciones en estas redes ultrasensibles. Gracias a la cantidad masiva de datos, LINNA aprende a generalizar en base a las propiedades de los metabolitos o a la vecindad genómica en lugar de mediante aproximaciones más rígidas y descriptivas usadas por los científicos humanos. Es esta capacidad de generalización la que le permite explorar millones de candidatos y enfrentarlos a diferentes regiones del interactoma del organismo de estudio, encontrando interacciones y respuestas no evidentes y de difícil comprensión para el humano.

Inteligencia Natural
Trabajamos de la mano de la Inteligencia Natural, capitalizando el conocimiento de miles de años de evolución, estudiando su comportamiento, iluminando aquellas moléculas desconocidas y obteniendo su riqueza a través de diferentes procesos y transformaciones como la pirólisis, la fermentación o las extracciones.
La botánica, la microbiología, las microalgas son universos repletos de potenciales compuestos que utilizaremos para formular las soluciones productivas del futuro.

Soluciones para tus retos
¿Para qué LINNA?
LINNA nace de las necesidades del mundo agrícola, pero sus aspiraciones y su potencial hacen que su aplicación sea extrapolable a la agroindustria, la dermocosmética o, incluso, la industria farmacéutica.
LINNA, por tanto, pretende dar respuesta a todos estos retos mediante la búsqueda de nuevos usos para el 1% de compuestos bioactivos conocidos, así como mediante la búsqueda de nuevos compuestos bioactivos entre ese 99% desconocido.
Más información sobre la finalidad de LINNA®
El enorme potencial de LINNA la hace capaz de buscar sinergias entre compuestos bioactivos, encontrar nuevos mecanismos de acción, predecir toxicidad y explotar las realidades no evidentes, es decir, aquellos patrones ocultos en la naturaleza indetectables para el ser humano mediante la observación tradicional.
Somos ambiciosos y el trabajo duro respalda nuestra ambición, para 2030 habremos analizado entre 3 y 5 millones de compuestos naturales. Entre estos compuestos pretendemos encontrar desde un nuevo herbicida que sustituya al glifosato hasta sustitutos de conservantes de síntesis química usados en la industria alimentaria.
¿Cómo funciona LINNA?
LINNA está compuesta por diferentes modelos predictivos perfectamente engranados entre sí con la intención de predecir la actividad de compuestos naturales y, por tanto, sugerir nuevos de estos compuestos para un reto determinado.
Para ello, obtenemos todo el espectro químico de diferentes materias primas naturales mediante diferentes procesos de extracción y transformación. Esto nos permite obtener más de 10 candidatos complejos por cada materia prima utilizada. Cada uno de estos candidatos, formados por cientos de compuestos desconocidos, provocan una respuesta diferente al ser aplicados en un organismo. El entendimiento de esta respuesta, mediante diferentes aproximaciones basadas en la biología de sistemas y la obtención de datos a gran escala (Big Data), permiten a LINNA® predecir el comportamiento de dicho organismo frente a un candidato diferente sin necesidad de ensayarlo.

1. DataDiscovery
2. DataShine
3. LINNABrain
4. LINNALearn
1. DataDiscovery.
Accede a datos internos y externos.
- Analizamos entre 3 y 5 millones de compuestos naturales, fruto de un nodo propio de generación y amplificación de candidatos. Dentro de esta acción colaborativa con la ciencia esto nos hace ser más competitivos. ¿Quieres saber cómo lo hacemos?
- Más de 500 TB de información transcriptómica
- Más de 130 millones de imágenes tomadas con sensores RGB, PAM y cámaras hiperespectrales
Toda esta información generada, junto al resto de datos externos, nos permitirá encontrar nuevos compuestos y mecanismos de acción desconocidos hasta el momento a la vez que reducimos, hasta en un 95% la necesidad de realizar ensayos experimentales
Datos internos
Un universo de datos propietario que convierte nuestra plataforma en única
Utilizamos los datos que hemos generado internamente en nuestro ecosistema de búsqueda de valor, como son los perfiles moleculares, la relaciones causa-efecto molécula natural-mode de acción frente a un objetivo, o el know-how de relaciones y sinergias entre moléculas naturales para generar elevada eficacia que llevamos desarrollando durante 15 años.
Datos externos
Fuentes de datos externos que nos ayudan a dar valor y encontrar patrones de relevancia
Como por ejemplo datos de históricos de temperaturas y sus relaciones con las cosechas, datos de seguimiento de explotaciones por cultivo gracias a IoTs, bases de datos externas de metabarcoding y etagenómica o relaciones estructura actividad de moléculas químicas.
2. DataShine.
Hace brillar los datos mediante diferentes modelos de machine learning (como modelos de regresión, de reducción dimensional o clustering no supervisado para realizar tareas diversas como la exploración del espacio químico de un candidato o caracterizar la respuesta transcriptómica en respuesta a la aplicación de un candidato) combinados con modelos de deep learning (como redes redes neuronales de grafo y encoders-decoders para potenciar las tareas de predicción de actividad biológica). Todos estos modelos se encuentran integrados formando 3 módulos que convierten a LINNA en una herramienta potente y versátil sin precedentes
La explotación de este módulo nos ha permitido encontrar 30 candidatos con alto poder herbicida a los que no hubiéramos llegado usando solo la lógica humana
Módulos que componen LINNA
LINNA se compone de tres módulos (expresión, reducción dimensional y fenotipo) que integran diferentes modelos en un pipeline único cuyo objetivo es la predicción de un fenotipo a partir de un candidato complejo, pero también, la sugerencia de nuevos compuestos bioactivos necesarios para lograr un fenotipo o actividad biológica determinada:
1. Expresión
Todos estos datos del candidato son usados para predecir el perfil de expresión que tanto el candidato en su conjunto como cada uno de los compuestos que lo integran generarían en el organismo de estudio.
2. Reducción dimensional
El perfil de expresión de un organismo en respuesta a un candidato, normalmente formado por cientos o incluso miles de compuestos, supone la obtención de varios miles de genes diferencialmente expresados. Si tomásemos cada uno de los genes como una entidad independiente, la predicción de un fenotipo sería prácticamente imposible. Dada esta complejidad, el segundo módulo presente en LINNA® usa el perfil de expresión predicho por el módulo 1 para hallar los principales procesos biológicos alterados y la importancia de los diferentes genes implicados en estos procesos. Este módulo permite reducir varios miles de genes diferencialmente expresados en unas pocas decenas de procesos biológicos alterados que incluyen todos esos genes y la manera de comportarse con su entorno biológico. De esta manera, se permite reducir la complejidad de computación del módulo 3 para la predicción de un fenotipo determinado.
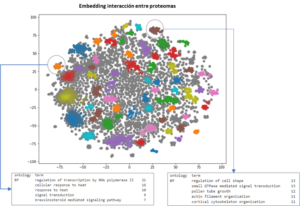
Representación de la reducción dimensional obtenida por el módulo 2 de LINNA® tras la predicción de más de 5000 genes diferencialmente expresados. Se observan los diferentes procesos biológicos alterados, los genes que lo componen, su ontología génica y las interacciones que las proteínas codificadas por dichos genes realizan entre sí.
3. Fenotipo
El tercer módulo usa como input los procesos biológicos alterados por el candidato de estudio para predecir una gran cantidad de parámetros fenotípicos. Los modelos matemáticos integrados en este módulo son capaces no solo de predecir dichos parámetros, sino de asignar la importancia relativa que cada uno de ellos tendrá en el fenotipo final.
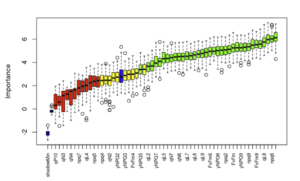
Asignación de importancia relativa para los parámetros fenotípicos predichos por el módulo 3 de LINNA®.
Todos estos parámetros, junto a su importancia relativa, permiten, en última instancia, agrupar al candidato de estudio (o cualquiera de sus compuestos bioactivos) según su actividad biológica o fenotipo esperado, pero, también, según su mecanismo de acción dentro de cada actividad biológica. Esta agrupación se compara con los resultados de expresión del módulo anterior, permitiendo encontrar correlaciones complejas entre respuesta transcriptómica y fenotípica en un espacio dimensional reducido.
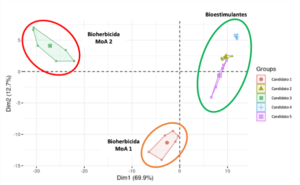
Agrupación, realizada por el módulo 3 de LINNA®, en actividades biológicas y mecanismos de acción de cinco candidatos ensayados partiendo de las predicciones de parámetros fenotípicos y su importancia relativa.
3. LINNABrain.
Nuestra lógica se basa en la inteligencia de negocio, las estrategias comerciales, las necesidades reales específica de la industria, la exigencia del mercado entre otros siguiendo razonamientos y lógicas únicas para aportar una solución 360 y que responda a una necesidad real de la industria
4. LINNALearn.
Aprende de las decisiones tomadas por LINNA Brain y optimiza sus resultados incrementando su capacidad de prescripción
Si realmente has llegado hasta aquí…

Estás obsesionado con el conocimiento
Eres de la competencia y seguro que…
Te has ofendido así que no sigas a nuestro CEO en Instagram

La transversalidad de LINNA
Aunque LINNA surge con la vocación de resolver retos agrícolas: desarrollo de bioherbicidas, bioestimulantes, probióticos, biofungicidas, bioinsecticidas y tratamiento de semillas, su enorme potencial la convierten en una plataforma transversal con capacidad para solucionar retos que se planteen en la industria ganadera, piscícola, cosmética o farmacéutica.
Nos adelantamos al futuro
Objetivo 2030
Analizar 3-5 millones de compuestos naturales con una capacidad de predicción superior al 95%
Beneficiarse de las realidades no evidentes, entendida como la capacidad de la IA de encontrar relaciones indetectables (ocultas) mediante la observación humana
Nace la posibilidad de gestionar y analizar una ingente cantidad de datos a partir de 15 años de experiencia en compuestos naturales
Búsqueda de la transversalidad, ya que las leyes de la biología son vigentes para todos los organismos
Indagar en el 99% de lo natural no conocido
Encontrar nuevos mecanismos de acción asociados a las moléculas naturales
Predecir posibles toxicidades de los productos
Buscar sinergias entre moléculas naturales
Nuevos usos para el 1% de lo natural conocido
Han visto el futuro
Kimon Theophanopoulus
CEO & Founder Teofert
Alexandre Macedo
Vicepresidente de bioestimulantes de Yara Europe
Ernesto Baltodano
Gerente general CISA Agro
Compuestos naturales bioactivos
Los compuestos bioactivos son moléculas químicas presentes en la naturaleza que exhiben actividades biológicas determinadas. Estos compuestos se han usado tradicionalmente en la alimentación, la dermocosmética o la industria farmacéutica.
Los compuestos bioactivos pueden ser producidos por diferentes organismos como plantas, hongos, bacterias y microalgas.
Entre ellos, destacan las plantas, por ser auténticas biofactorías de fitoquímicos (compuestos bioactivos producidos por dichas plantas). Estos fitoquímicos son sintetizados de forma natural por las plantas como parte de su metabolismo secundario; es decir, como parte de aquellas reacciones químicas que dan lugar a diferentes moléculas que, pese a no ser esenciales para la vida de la planta, cumplen una serie de funciones clave en la supervivencia de éstas, como, por ejemplo, la adaptación a condiciones ambientales cambiantes, la defensa frente a patógenos o la polinización mediante la síntesis de diferentes pigmentos.
Si hablamos de microorganismos y microalgas, actualmente solo conocemos un 1% de los mismos. Gracias a LINNA® podemos buscar nuevos usos de los compuestos ya conocidos procedentes de microorganismos y microalgas, y además, descifrar el 99% de los microorganismos y de sus compuestos, de los que aún carecemos de conocimiento. Sin duda, un enorme potencial por descubrir.
Algunos de estos fitoquímicos son:
- El ácido salicílico, una molécula obtenida de la corteza del sauce y usada en dermocosmética para tratar el acné por sus propiedades antiinflamatorias y antibacterianas.
- La quinina, obtenida de la corteza de árboles del género Cichona y usado como antimalárico, pero también como ingrediente de champús anticaída o como potenciandor del sabor de la tónica.
- La morfina, potente analgésico obtenido de la planta adormidera (Papaver somiferum).
- La artemisina, obtenida de la planta Artemisia annua, usada en un nuevo tratamiento de la malaria y cuyo descubrimiento le otorgó el premio Nobel de Medicina en 2015 a Tu Youyou.
Inteligencia Artificial
La Inteligencia Artificial permite analizar millones de datos y descubrir patrones ocultos en ellos. Es por eso por lo que LINNA® cuenta con multitud de algoritmos y modelos predictivos que incluyen tanto machine learning como deep learning. De esta manera, LINNA® integra modelos de regresión, reducción dimensional y clustering no supervisado para realizar tareas tales como la exploración del espacio químico de un candidato o la caracterización de la respuesta trancriptómica de un organismo ante la aplicación de dicho candidato. Estos modelos de machine learning son combinados con redes neuronales de grafo y encoders-decoders que permiten potenciar la capacidad predictiva y convierten a LINNA® en una herramienta potente y versátil sin precedentes.
Un método de investigación disruptivo que cambia la manera de hacer ciencia.
Futuro
Aceleramos el proceso de investigación
Conocimiento
Reducimos el margen de error y retenemos conocimiento indefinidamente
Para ello, LINNA® trabaja de la mano de la Inteligencia Natural, capitalizando el conocimiento adquirido durante 15 años de estudio de los procesos necesarios para obtener todo el espectro químico de las materias primas naturales, del entendimiento de los compuestos bioactivos y de la formación de sinergias entre ellos. Con LINNA®, toda nuestra Inteligencia Natural está potenciada por la Inteligencia Artificial creando, así, una herramienta única en el sector. La botánica, la microbiología y las microalgas son universos repletos de potenciales compuestos desconocidos que LINNA® decodificará y utilizará para formular las soluciones productivas del futuro.
Compuestos naturales analizados
LINNA habrá analizado para 2030 entre 3 y 5 millones de compuestos naturales, generado más de 500 TB de información transcriptómica y más de 130 millones de imágenes tomadas con sensores RGB, PAM y cámaras hiperespectrales. Toda esta información, tras ser cruzada con nuestras bases de datos, nos permita encontrar nuevos compuestos y mecanismos de acción desconocidos hasta el momento a la vez que reducimos, hasta en un 95%, la necesidad de realizar ensayos experimentales.
Nuestras bases de datos, generadas para dotar a LINNA® de toda la información que necesita para afrontar sus predicciones, incluyen:
+450.000
moléculas naturales
+270 millones
moléculas sinteticas
+200 millones
todas las proteínas e isoformas de estas proteínas estudiadas hasta el momento.
+2000
genomas y proteomas de diferentes especies tanto vegetales cómo fúngicas, bacterianas o animales.
+2 billones
de interacciones proteína-proteína
+500
rutas metabólicas conservadas.
Aprende más sobre el funcionamiento de LINNA
El núcleo de LINNA se basa en la biología de sistemas; es decir, en el estudio holístico de un sistema biológico con la intención de obtener una mejor comprensión de éste y, por tanto, facilitar la posibilidad de predecir su comportamiento en un futuro. Para ello, LINNA® se apoya en modelos matemáticos que complementan las estrategias biológicas permitiendo predecir propiedades y comportamientos de los seres vivos que podrían no ser deducibles mediante observación directa.
Los organismos vivos son muy complejos y entenderlos en profundidad no es una tarea sencilla. Para desentrañar esta complejidad, LINNA es alimentada con datos biológicos a gran escala, conocidos como datos ómicos, los cuales constituyen la base de las predicciones realizadas por los modelos matemáticos.
Aprende más sobre los datos que alimentan a LINNA
Los candidatos naturales ensayados frente a diferentes retos constituyen la piedra angular de LINNA y una de las fuentes de datos que alimentan sus modelos predictivos. Es, por ello, esencial caracterizar el perfil químico de estos candidatos, localizando todos los compuestos que forman parte de éstos. Con este fin, todos los candidatos son estudiados en profundidad mediante diferentes técnicas de espectrometría de masas.
Por otra parte, la aplicación de estos candidatos genera una serie de cambios en el organismo ensayado, a nivel molecular en primer lugar y a nivel fenotípico en última instancia. Por ello, de cada organismo tratado con un candidato determinado, obtenemos datos transcriptómicos mediante secuenciación masiva y datos fenómicos mediante cámaras robotizadas de fenotipado. Estos datos ómicos, son analizados mediante diferentes aproximaciones bioinformáticas para, finalmente, alimentar los modelos predictivos desarrollados e integrados en LINNA. Así, LINNA es capaz de relacionar la actividad de cada uno de los compuestos presentes en un candidato complejo con un perfil de expresión y, éste, a su vez, con unos cambios fenotípicos determinados.
Perfil químico
El perfil químico consiste en la caracterización en profundidad, a nivel molecular, de un candidato. Para ello, se analiza tanto el perfil volátil mediante cromatografía de gases – espectrometría de masas (GC-MS), como el resto de los compuestos presentes en el candidato mediante cromatografía líquida-espectrometría de masas con cuadrupolo-tiempo de vuelo (Q-TOF). Este equipo de espectrometría de masas de alta resolución nos permite llevar a cabo la detección de un gran número de compuestos presentes en un candidato. Esta detección y posterior identificación de compuestos alimentan una base de datos interna sobre la que LINNA basará sus sugerencias de nuevos compuestos haciendo uso de su integración con otras bases de datos de compuestos naturales existentes.
La combinación de estas técnicas de espectrometría de masas nos permite adquirir un conocimiento exhaustivo de la composición de un candidato que podrá relacionarse, mediante los modelos predictivos integrados en LINNA, con un perfil de expresión o transcriptoma y un fenotipo determinado.
Fenotipado
El fenotipo es la apariencia externa de un organismo y comprende todas las características visibles y medibles que se pueden evaluar sin dañar al organismo de estudio. Esto incluye recuentos, dimensiones, colores y otras propiedades que brindan información estructural. Además, el fenotipo incluye la obtención de características fisiológicas o propiedades bioquímicas mediante procedimientos no invasivos.
LINNA utiliza datos fenómicos obtenidos gracias a una plataforma de fenotipado robótica que integra sensores RGB, PAM y cámaras hiperespectrales y que nos permiten obtener una visión global de todas aquellas características fenotípicas que ocurren en un organismo como respuesta a la aplicación de un candidato. Así, por ejemplo, podemos obtener información sobre el contenido protéico, el contenido de agua o el funcionamiento de la fotosíntesis de una planta a la que se le ha aplicado un candidato determinado, algo esencial para que LINNA sea capaz de desentrañar sistemas biológicos tan complejos como las plantas.
Secuencia masiva
La secuenciación masiva engloba todos los métodos de secuenciación de ácidos nucleicos a gran escala y de manera paralelizada.
Los modelos predictivos de LINNA son alimentados con datos de secuenciación masiva, más concretamente datos de transcriptómica, una técnica que permite examinar la presencia y cantidad de todas las moléculas de ARN presentes en una muestra biológica en un momento determinado.
Bioinformática
La bioinformática se convierte en esencial con la obtención de datos biológicos a gran escala, como el caso de los datos transcriptómicos y fenómicos que alimentan a LINNA. Con la intención de no generar sesgos humanos, lo que podría provocar desviaciones indeseadas en las predicciones, contamos con flujos de trabajo desarrollados especificamente para analizar y estructurar de manera automatizada los datos transcriptómicos y fenómicos que alimentan los modelos predictivos integrados en LINNA.
Aprende más sobre la transversalidad de LINNA
La transversalidad es una de las características distintivas de LINNA. No sólo es capaz de predecir la actividad de compuestos y sugerir nuevos compuestos para uso agrícola, sino que también es capaz de hacerlo para cualquier reto que le planteemos.
Para ello, nuestros candidatos no solo se ensayan en plantas, sino que también se ensayan sobre una serie de organismos modelo cuidadosamente seleccionados con la intención de obtener información molecular de la respuesta de estos organismos ante el candidato ensayado.
Con esta información molecular y la aplicación de un modelo matemático desarrollado para este fin, LINNA es capaz de predecir, con una precisión sorprendentemente elevada, los cambios moleculares que ocurrirían en otros organismos si ensayáramos estos candidatos sobre ellos.
Aprende más sobre los modelos predictivos aplicados a la transversalidad de LINNA®
Aprende más sobre los modelos predictivos aplicados a la transversalidad de LINNA
Los organismos modelo son organismos ampliamente utilizados por los investigadores para estudiar procesos biológicos concretos.
Jacques-Lucien Monod decía que “Todo lo que se constata como veraz para Escherichia coli también debe ser cierto para los elefantes”. Esta afirmación con relación a los descubrimientos basados en la regulación de la expresión génica en bacterias, pero que eran extrapolables a todos los seres vivos, le llevaron a ganar el premio Nobel de Medicina en el año 1965 y han sido la inspiración para el desarrollo del modelo matemático predictivo relacionado con la transversalidad de LINNA.
A través de la información transcriptómica del organismo modelo en respuesta al candidato ensayado, la anotación de ortólogos entre dicho organismo modelo y el organismo de destino y la vecindad genómica de ambos organismos, hemos generado e integrado en LINNA un modelo matemático con capacidad para predecir los cambios diferenciales de expresión que cualquier candidato generará en otro organismo sin necesidad de repetir el ensayo sobre éste.